开云官网切尔西赞助商新能源汽车的电板、光伏组件、稀土加工-开云官网kaiyun皇马赞助商 (中国)官方网站 登录入口

01开云官网切尔西赞助商
本周末有一条 AI 新闻挺专诚想,跟各人聊聊。
AI 编程器具 Cursor 在 3 月 19 日发布了新模子 Composer 2,官网上写的是「自有模子」。
Cursor 是咫尺全球最火的 AI 编程器具,骨子上是一个深度集成了 AI 才能的 VS Code 修改版(国内访佛的是字节的 TRAE)。从 2024 年 10 月 Composer 1 发布以来,外界就一直怀疑它的模子是套壳的,但找不到字据。
此次字据来了。发布不到 24 小时,一位开发者 @fynnso 想了个奥妙的办法:我方架一台劳动器充任模子接口,然后在腹地 Cursor 里把模子地址指向我方的劳动器。这样 Cursor 发出的肯求就浮现了:模子 ID 是 kimi-k2p5-rl-0317-s515-fast。
Composer 2 的底座,是月之暗面的 Kimi K2.5。
截图传开后,Cursor 第一时候堵了罅隙,但没什么用了。马斯克也转发阐发。
Cursor 的一位厚爱东说念主最终回话,承认使用了 K2.5,但强调是通过巴合股伴 Fireworks AI 取得的正当授权。Kimi 官方也阐发了这条授权链。从法律层面看,Cursor 并莫得侵权。
对于这件事的探究其实许多了,但我想聊另一个视角。
02
往时两年,AI 领域有一条暗线。
2023 年,国内 AI 创业的主流姿态是拿 Meta 的 Llama 作念微调。那时候行业的共鸣是「落伍硅谷两个世代」。
2024 年 5 月,DeepSeek 发布了 V2。这家从量化基金幻方孵化出来的公司,用 MoE(羼杂巨匠模子)和 MLA(多模态学习架构)两项时间把模子的调用资本大幅压低。MoE 的逻辑我在之前的 DeepSeek 小传里写过,简短说即是不让大模子当全才,而是让它成为一个巨匠团,需要谁就叫醒谁。MLA 则大幅镌汰了内存占用,显存压力比传统架构镌汰了 67%-90%。
其时各人对 DeepSeek 的印象主要照旧「低廉」。到 12 月 V3 发布,通常了 FP8 低精度检修等新时间,官方露馅的完好意思检修资本是 557.6 万好意思元,大致是 Meta Llama 3.1 检修资本的十分之一,性能却跟 GPT-4 基本握平。
然后是 2025 年 1 月,R1 发布。
R1 为什么关键,我在小传里也讲过。最中枢的小数:它用纯强化学习(pure RL)达到了 OpenAI o1 的推理水平,不需要东说念主工标注的题库,不需要有监督的微调,让模子我方跟我方博弈,我方评估什么是好的谜底。这不是「我用更少的钱作念了你作念过的事」,而是「我走了一条没东说念主走过的路」。
R1 之后,OpenAI 的奥特曼从最初暗讽 DeepSeek「仅仅复制已知责任」,到自后承认「DeepSeek 的出现改变了往时几年 OpenAI 遥遥率先的情况」。Meta 据报说念建设了多个专项小组拆解 DeepSeek 的方法。
这是第一波。
第二波来自 Kimi。2026 年 1 月底,K2.5 发布。万亿参数的 MoE 模子,原生多模态,在代码生成、视觉知道和 Agent 器具调用上进展王人可以。关节是它开源了,接管 Modified MIT 合同。
发布后不久,K2.5 在 OpenRouter(一个全球开发者用来选拔和调用 AI 模子的团员平台)的调用量冲到了第又名,排在 Gemini 3 Flash 和 Claude Sonnet 4.5 前边。固然,其时 K2.5 在 OpenClaw 生态里可以免费调用,这对调用量的拉动作用不小。
三年前,国内公司拿着 Llama 作念微调。当今,硅谷的头部器具拿着 K2.5 作念微调。这个变化的速率,超出了大多数东说念主的预期。亦然咱们许多东说念主之前没料想的。
03
讲到这里就要说到一个更基础的问题了:开源模子的「供应链」到底是什么?
大多数东说念主对「开源」的知道停留在:免费下载,我方用。会觉得 DeepSeek 和 Kimi 的价值即是「帮家东说念主们把价钱打下来了」。
早先,这固然没错,但真实的生意寰球里,开源模子的流转旅途远不啻于此。
以 Cursor 这个案例为例,完好意思的链条是这样的:
Kimi 开源 K2.5 → 硅谷的推理劳动商 Fireworks AI 取得授权,作念托管、微谐和强化学习检修 → Fireworks AI 转授权给 Cursor → Cursor 包装成 Composer 2 提供给全球开发者。
中间每一层王人偶然间劳动、有授权合同、有生意利益分拨。这依然是生意步履,不是公益步履。
动作生意步履,开源模子的供应链正在像往时实体制造领域的中国供应链一样,在全球产生影响。
一件优衣库的一稔,从纱线到面料到裁缝,供应链也在中国。新能源汽车的电板、光伏组件、稀土加工,全球阛阓对中国供应链的依赖进度很深。
这种依赖的变成是靠几十年累积出来的资本上风、工程才能和畛域效应。全球品牌选拔中国供应链,跟心爱跟谁交一又友联系不大,照旧一笔经济账,即同样的品性,资本更低;同样的资本,托福更快。
AI 领域正在出现一个结构上有些访佛的面目,原材料不是钢铁和棉花,是模子权重和推理算力。全球的 AI 期骗层公司开动选拔中国的开源模子作念底座,驱能源也很朴素,即是好用,低廉。
其实在科技领域是有知名的前例的: Android。Google 开源 AOSP,高通作念芯片适配,三星华为作念拓荒定制,运营商作念渠说念。用户手里拿到的是一台三星手机,但操作系统的底层逻辑、API 门径和生态圭臬是 Google 界说的。供应链上每一层王人在赢利,界说底座的那一层,谈话权也极端大。
固然这还仅仅一个可能的标的,不是既成事实。还有很远的路要走。
04
说到 AI 供应链,当然就要提到 2026 年开年的第一个 AI 大火的领域,养龙虾。
OpenClaw 是一个开源 Agent 框架,奥地利开发者 Peter Steinberger 的作品。龙虾需要一个大脑,或者说需要喂养饲料。OpenClaw 自己是框架,不提供模子,用户得我方选。
K2.5 成了 OpenClaw 官方保举的主力模子。大厂跟进,字节的 ArkClaw、腾讯的 QClaw、智谱的 AutoClaw、MiniMax 的 MaxClaw、阿里的 CoPaw……2026 年 3 月密集上线。其中底层调用量最大的模子里就包括了 K2.5、DeepSeek、Qwen 系列、MiniMax。开源模子握续占据了 token 流量的主流。
这条链路跟实体供应链也有一些相似之处。富士康给苹果代工,也给华为代工,也给小米代工。谁的手机卖得好,富士康王人赢利,因为它在供应链的位置饱和底层。
若是说 Cursor 事件浮现的是 B 端供应链里的故事,龙虾生态展示的是 C 端供应链里的故事。两条链路指向并吞个事实:底座模子的位置,越来越像基础纪律了。
从龙虾也能看得出,基础纪律的叙事也渐渐变成现实。token 即畴昔 AI 时间的水电煤。
这个「水电煤」的阛阓到底有多大?有一组数据可以参考。
据华泰柏瑞基金的统计,中国举座日均 Token 消费从 2024 年头的大致 1000 亿,到 2025 年年中打破 30 万亿,2026 年 2 月照旧到了 180 万亿的量级。龙虾这类 Agent 期骗每天全天候运行,消费的 Token 量比往时的 Chatbot 对话越过几个数目级。
3 月 16 日,阿里布告建设 Alibaba Token Hub(ATH)奇迹群,跟电商、云智能并排,由 CEO 吴泳铭平直带队。总共奇迹群围绕一件事:创造 Token、运输 Token、期骗 Token。通义实验室造模子,MaaS 业务线搭平台,千问作念 C 端,新建设的悟空奇迹部作念 B 端。
Token 这个词以前只在时间社区里用,当今被一家万亿市值的公司拿来定名中枢奇迹群。
若是 Token 真实在变成 AI 时间的水电煤,那谁能雄厚、低资腹地提供多数 Token,谁就在这个生态里有位置。开源模子在这件事上有自然上风:部署天真、资本可控、不依赖单一供应商。DeepSeek 和 Kimi 这类把资本打下来同期保握性能的开源模子,就极端于这个阛阓里的低资本发电厂。他们会是这个阛阓里相等关键的一类玩家。
05
为什么中国的开源模子会受接待?
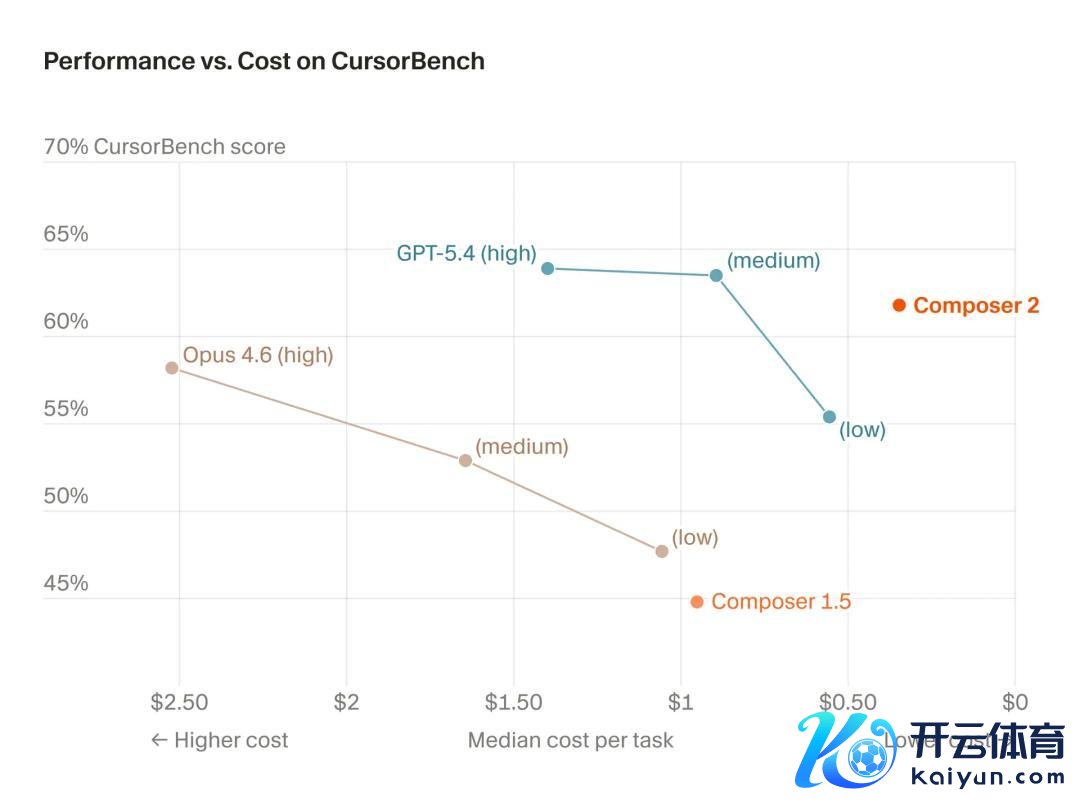
Cloudflare 作念过实测,在 Workers AI 平台上用 K2.5 替代其他模子,推理资本镌汰了 77%。Cursor 我方露馅的数据也讲解了选拔逻辑:Composer 2 性能略低于 GPT-5.4,但生成速率更快,资本最低。对一家年化收入 20 亿好意思元的公司来说,这笔账很好算。
再看龙虾生态。K2.5 在 OpenRouter 的订价大致是每百万输入 token 0.5 好意思元、输出 2.8 好意思元。Claude Sonnet 4.5 是 3 好意思元和 15 好意思元。差六到七倍。龙虾的使用场景是高频调用,一个复杂任务可能要跑上百步致使上千步。在这种场景下,六倍的资本互异不是「省小数」的问题,是「能弗成奉侍它跑得起来」的问题。
这跟 DeepSeek 当年打下来的价钱基础一脉通常。V3 把每百万 token 的价钱打到了东说念主民币个位数,R1 更是把推理模子的价钱拉到了 OpenAI o1 的几十分之一。其时我写 DeepSeek 小传的时候提过,任何一个阛阓里出现这样的价差,王人会引起剧烈震撼。2.6 万块钱的手机当今只卖 1000 块钱,试想这种冲击力。
光低廉就怕也不行。
DeepSeek 用阿谁价钱提供的,是跟行业顶尖家具同等水平的劳动。K2.5 亦然一样,Cursor 的 Composer 2 在 Cursor 我方官方的测试 CursorBench 上的得分卓绝了 Claude Opus 4.6,而它的底座即是 K2.5。
这听起来似乎在说 K2.5 比 Claude 更强,固然也弗成这样说。毕竟跟多数东说念主用 ChatBot 的体感应该是不一样的。
Cursor 副总裁 Lee Robinson 在回话中提到,最终模子唯独大致 1/4 的算力来自底座,剩下 3/4 是 Cursor 我方作念的链接预检修和大畛域强化学习。
联合创举东说念主 Aman Sanger 进一步解说,团队在多个底座上作念了评估,K2.5 在编程关联的方针上进展最强,然后在此基础上作念了针对编程场景的链接预检修(改动任务散布和才能侧重)和 4 倍算力的强化学习检修。经过这些处理之后,Composer 2 在各项 benchmark 上的进展跟原始的 K2.5「照旧相等不同了」。
换句话说,Cursor 选 K2.5 不是因为它「比 Claude 贤人」,而是因为它动作底座在编程方进取的后劲最佳,经过多数定向检修之后能达到很高的性价比,能接近顶尖闭源模子,但资本低得多。
这其实亦然总共开源生态的价值方位:不需要从零检修一个千亿参数的模子,拿一个强底座作念垂直场景的深度优化,就能在特定任务上跟闭源巨头打得有来有回。Cursor 不是惟一这样作念的,Cognition 的 Windsurf 也接管了访佛旅途。
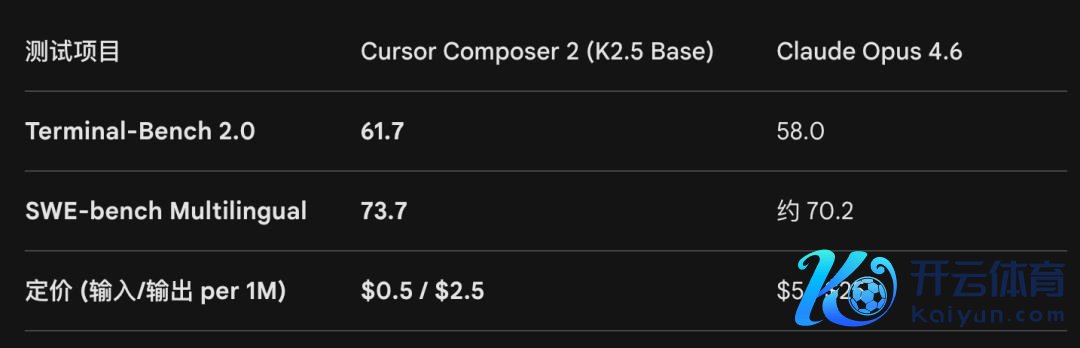
DeepSeek 在资本端大开的空间,K2.5 在 Agent 和代码两个关节场景里进一步蔓延了,组成了中国 AI 供应链的基本叙事。Kimi 的 K2.5 发布后得到了极高的关怀,20 天收入卓绝 2025 全年。国际收入初度反超国内。三个月内估值从 43 亿好意思元涨到 180 亿。
说到估值,有一个对比值得想想。
Cursor 的新一轮融资传言估值 500 亿好意思元。它的估值历程是:2023 年 10 月 5000 万,2024 年 8 月 4 亿,12 月 26 亿,2025 年 11 月 293 亿。火箭式增长。
支握这个增长的叙事很关键,「咱们有我方的模子研发才能」。Composer 1 和 Composer 2 王人在强化这个故事。
而提供底座的 Kimi,估值 180 亿好意思元,大致是 Cursor 主张估值的三分之一。放在供应链的语境里看,这就好比一个品牌商的市值是中枢供应商的三倍,但品牌商的家具中枢来自这个供应商。不是说这个比例一定不对理,Cursor 的家具力、用户粘性和生意模式照实有自身的价值,但至少讲解阛阓对「底座」和「壳」的订价,可能还存在一些理会上的时候差。
访佛的情况不啻 Cursor 一家。前段时候很火的 Manus,主打 AI Agent,也莫得我方的底层模子,统统依赖第三方。就因为家具和场景受到认可,被 Meta 开出了 20 亿的价码。
更值得关怀的是横向对比。Kimi 180 亿好意思元,大致是 OpenAI 的 2%,Anthropic 的不到 10%。DeepSeek 咫尺莫得公开融资,梁文锋用幻方的资金自力新生,84% 的控股简直没被稀释。这种独处性让他可以不受投资东说念主压力,专注长久接续。
这两家公司的底层时间输出正在被全球使用,它们的阛阓订价,还在被「全球 AI 基础纪律提供商」这个身份重估。
不外也有一种统统不同的看法:模子层最终会变成巨额商品(commodity),着实的价值在离用户更近的期骗层和数据层。按照这个逻辑,Cursor 的估值正巧反应了它离用户更近、离钱更近。两种判断王人有各自的真谛,现不才论断可能为时过早。
06
为什么小公司也有作念模子的时间契机呢?
3 月中旬,杨植麟受黄仁勋邀请在英伟达 GTC 大会演讲,是惟一受邀的中国大模子公司代表。他讲的是 Kimi 团队刚发表的论文《Attention Residuals》。

这篇论文的切入点很专诚想。残差聚拢是深度学习领域从 2015 年 ResNet 提议后就一直沿用的基础架构组件,10 年来简直没东说念主质疑它。大多数团队选拔在瞩见识机制、MoE 这些表层模块上作念优化,Kimi 在尝试从最底层的默许确立去找空间。
马斯克和 Karpathy 王人点赞了这篇著作。而论文的一作是一个 17 岁的高中生。
除了 Attention Residuals,Kimi 还开源了 MuonClip(替代用了 11 年的 Adam 优化器)和 Kimi Linear(线性瞩见识有规画)。杨植麟在 GTC 上把这些统称为 Scaling Ladder,即通过严谨的畛域化实验,从那些看似照旧定型的基础时间里,找到新的阅兵空间。
把 DeepSeek 和 Kimi 放在一说念看,能看到一个互补的花式。DeepSeek 的孝敬主要在检修方法论层面,pure RL 再行界说了推理模子奈何检修,MoE 和 MLA 的极致工程把检修资本压到了行业的十分之一。Kimi 的孝敬主要在网罗架构的基础组件层面,从残差聚拢到优化器到瞩见识机制,在最底层作念更始。
这两类责任有一个共同特色:它们王人不是在跑分榜上争排行,而是在作念范式层面的事情。梁文锋说过,许多东说念主以为 AI 即是鼎力出遗迹,但着实的打破往往还自更奥妙的方法,而不是更多的资源。杨植麟在 GTC 上也抒发了访佛的真谛:10 年前作念接续主要靠发表新想法,但穷乏严谨的大畛域实验来考据。当今有了充足的揣度资源和 Scaling Ladder 方法论,大略更严格地从那些看似「照旧定型」的时间里找到阅兵空间。
这跟国内许多大厂作念模子的旅途有些不同。大厂的资源更充裕,家具线也更丰富,但中枢动作常常是围绕我方的业务作念集成和优化。在「回到第一性旨趣去挑战底层假定」这件事上,受限于业务压力和组织惯性,大厂很难给出饱和的空间和耐烦。
回到供应链的类比。实体制造业的供应链里,着实有握久谈话权的不是拼装厂,而是界说中枢零部件和时间圭臬的那一层:台积电的先进制程,高通的基带芯片,ARM 的提醒集架构。AI 的供应链也一样,若是底座模子不仅仅「好用又低廉」,还在输出底层的时间组件和方法论,那它在供应链里的位置就不仅仅一个供应商,而更接近基础纪律和圭臬制定者了。
固然,这还仅仅一个趋势,远莫得到可以下论断的进度。
07
终末说几句开源的畴昔。
开源不是一件跋扈的事。它需要几个条目同期闲适:时间上得有饱和强的模子,开源出去才有东说念主用;生意上得忍得住短期让利的「亏空期」;策略上弗成被价钱战和短期竞争带偏。
比如 MiniMax 的最新模子 M2.7 照旧转闭源了,权重不再公开。
前不久千问发生的事也一定进度讲解了开源濒临的挑战。3 月初,阿里千问的时间厚爱东说念主林俊旸布告下野,主流的说法是,时间设想和公司策略 KPI 之间存在不可谐和的冲突。
Meta 方面,围绕 Llama 4 的测试和道路出现了里面争议,据报说念 Meta 下一代模子可能转向闭源。大厂作念开源,似乎总会际遇同样的问题:短期里,措置层很出丑到开源的平直收益;长久里,开源团队很难按大厂的节律陈诉恶果。
即便有了生意闭环,开源模子的窗口期仍然有许多不细则要素。地缘政事在收紧,DeepSeek 照旧在一些国度被结果使用,好意思国有盘问员公开号召加强对华 AI 经管。
竞争敌手也在发力,OpenAI 在加快推出新模子。投资东说念主的耐烦也有限,不是每个激动王人能禁受「先让全寰球免用度,长久再赢利」这种延迟闲适的逻辑。
若是畴昔更多的模子公司转向闭源,那些照旧依赖上中国开源模子的全球期骗层公司和开发者,就需要再行找有规画了。
那么不管是 Cursor 和龙虾对 Kimi 模子的调用,照旧前年的 DeepSeek 的胆寒全球,中国开源模子到底意味着什么呢?
探究时,很容易走向两个顶点。一边有东说念主带着民族热沈说赢麻了,一边可能从纯时间视角判断并莫得新的范式因此不外如斯。开源模子当然有其场景价值,也有其局限和问题。着实的畴昔,是时间+生意+家具逼迫迭代变化中发生的。
咫尺能看到的是,全球 AI 的基础纪律正在从「好意思国提供模子,全寰球作念期骗」的单一结构,平安变成一个参与方更多、档次更复杂的供应链体系。DeepSeek 和 Kimi 为代表的中国开源模子,是这个变化里的关键变量。但也仅仅变量之一。
这个流程才刚刚开动。也期待 AI 供应链能跑出不同的时间竞争力,正如许多全球知名的智能硬件品牌,亦然珠三角供应链水平的外溢一样。
而这些更低廉、性能在握续追平的开源模子正在支握许多主流编程器具和 Agent 框架。
对于咱们这些等闲从业者、开发者、内容坐褥者来说开云官网切尔西赞助商,最施行的收货可能即是:咱们能更低廉地用上更多的 AI 家具。


